C++
strcpy和memcpy的区别
1、复制的内容不同。strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。
2、复制的方法不同。strcpy不需要指定长度,它遇到被复制字符的串结束符”\0”才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度。
3、用途不同。通常在复制字符串时用strcpy,而需要复制其他类型数据时则一般用memcpy
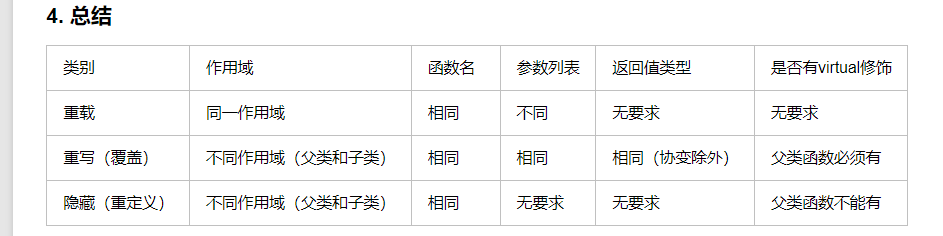
重载、重写、隐藏的区别
参考 重载、重写和隐藏三者的区别 - evenleo - 博客园 (cnblogs.com)
指针和引用的区别
| 指针 | 引用 |
|---|---|
| 存的是一个地址 | 是原变量的别名 |
| 可以有多级 | 只有一级 |
| 可以为空 | 不能为NULL且在定义时必须初始化 |
| 在初始化后可以改变指向 | 在初始化之后不可再改变 |
| sizeof指针得到的是本指针的大小 | sizeof引用得到的是引用所指向变量的大小 |
| 声明和 定义可以分开,可以先只声明指针变量而不初始化,等用到时再指向具体变量 | 在声明时必须初始化为另一变量 |
new和malloc的区别
| new | malloc |
|---|---|
| 运算符,不重载 | 标准库函数,支持覆盖 |
| 除了分配,还会调用构造函数和析构函数 | 仅仅分配内存空间 |
| 返回的是具体类型指针 | void类型指针 |
| 自动计算要分配的空间大小 | 需要手工计算 |
inline函数和宏定义的区别

多态
C++ 多态分类及实现:
- 重载多态(Ad-hoc Polymorphism,编译期):函数重载、运算符重载
- 子类型多态(Subtype Polymorphism,运行期):虚函数
- 参数多态性(Parametric Polymorphism,编译期):类模板、函数模板
- 强制多态(Coercion Polymorphism,编译期/运行期):基本类型转换、自定义类型转换
静态多态(编译期/早绑定)
函数重载
动态多态(运行期期/晚绑定)
- 虚函数:用 virtual 修饰成员函数,使其成为虚函数
- 动态绑定:当使用基类的引用或指针调用一个虚函数时将发生动态绑定
虚函数实现多态的原理
(1)编译器在发现基类中有虚函数时,会自动为每个含有虚函数的类生成一份虚表,该表是一个一维 数组,虚表里保存了虚函数的入口地址
(2)编译器会在每个对象的前四个字节中保存一个虚表指针,即vptr,指向对象所属类的虚表。在构 造时,根据对象的类型去初始化虚指针vptr,从而让vptr指向正确的虚表,从而在调用虚函数时,能找到 正确的函数
(3)所谓的合适时机,在派生类定义对象时,程序运行会自动调用构造函数,在构造函数中创建虚表 并对虚表初始化。在构造子类对象时,会先调用父类的构造函数,此时,编译器只“看到了”父类,并为 父类对象初始化虚表指针,令它指向父类的虚表;当调用子类的构造函数时,为子类对象初始化虚表指 针,令它指向子类的虚表
(4)当派生类对基类的虚函数没有重写时,派生类的虚表指针指向的是基类的虚表;当派生类对基类 的虚函数重写时,派生类的虚表指针指向的是自身的虚表;当派生类中有自己的虚函数时,在自己的虚 表中将此虚函数地址添加在后面 这样指向派生类的基类指针在运行时,就可以根据派生类对虚函数重写情况动态的进行调用,从而实现 多态性。
构造函数与析构函数的区别
- 构造函数 ,是一种特殊的方法。主要用来在创建对象时初始化对象, 即为对象成员变量赋初始值,总与new运算符一起使用在创建对象的语句中。特别的一个类可以有多个构造函数 ,可根据其参数个数的不同或参数类型的不同来区分它们 即构造函数的重载。
- 析构函数(destructor) 与构造函数相反,当对象脱离其作用域时(例如对象所在的函数已调用完毕),系统自动执行析构函数。析构函数往往用来做“清理善后” 的工作(例如在建立对象时用new开辟了一片内存空间,应在退出前在析构函数中用delete释放)
单例模式
参考 https://www.cnblogs.com/xiaolincoding/p/11437231.html
1 | ////////////////////////// 饿汉实现 ///////////////////// |
计算机网络
TCP与UDP的区别
| TCP | UDP |
|---|---|
| 面向连接 | 无连接的 |
| 提供可靠的服务 | UDP尽最大努力交付 |
| 面向字节流 | 面向报文 |
| 有拥塞控制 | 没有拥塞控制 |
| TCP连接只能是点到点的 | UDP支持一对一,一对多,多对一和多对多的交互通信 |
| TCP首部开销20字节 | UDP的首部开销只有8个字节 |
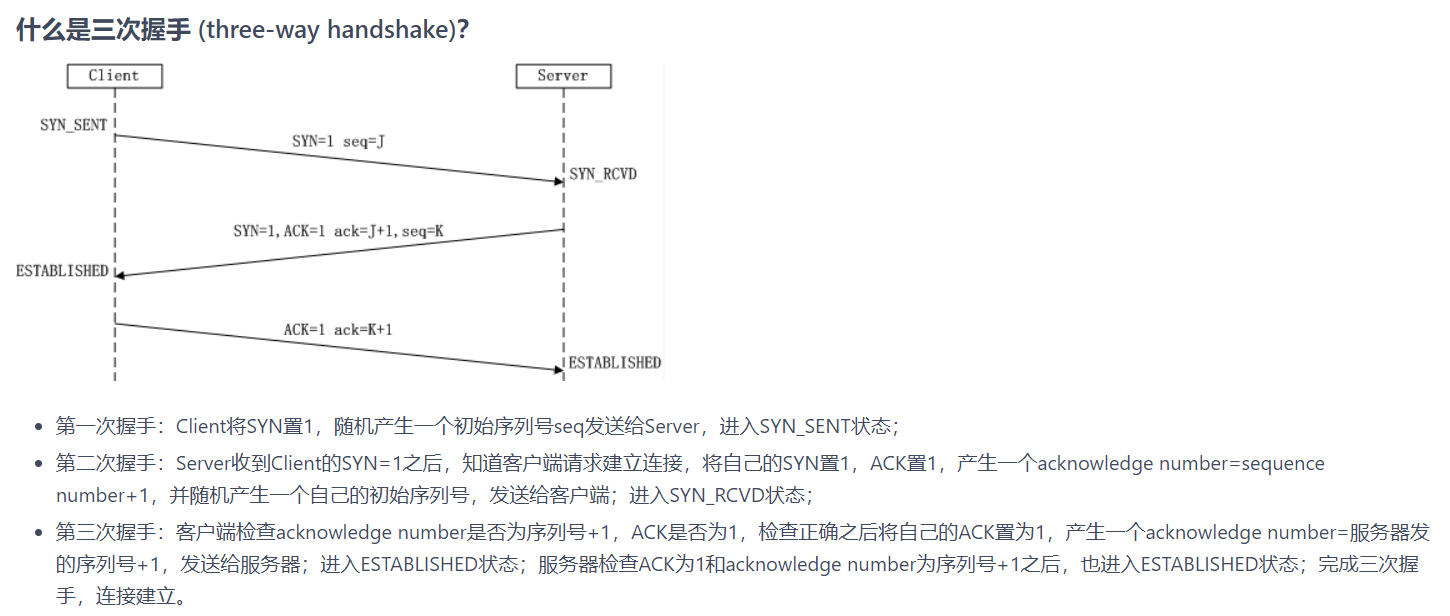
TCP三次握手
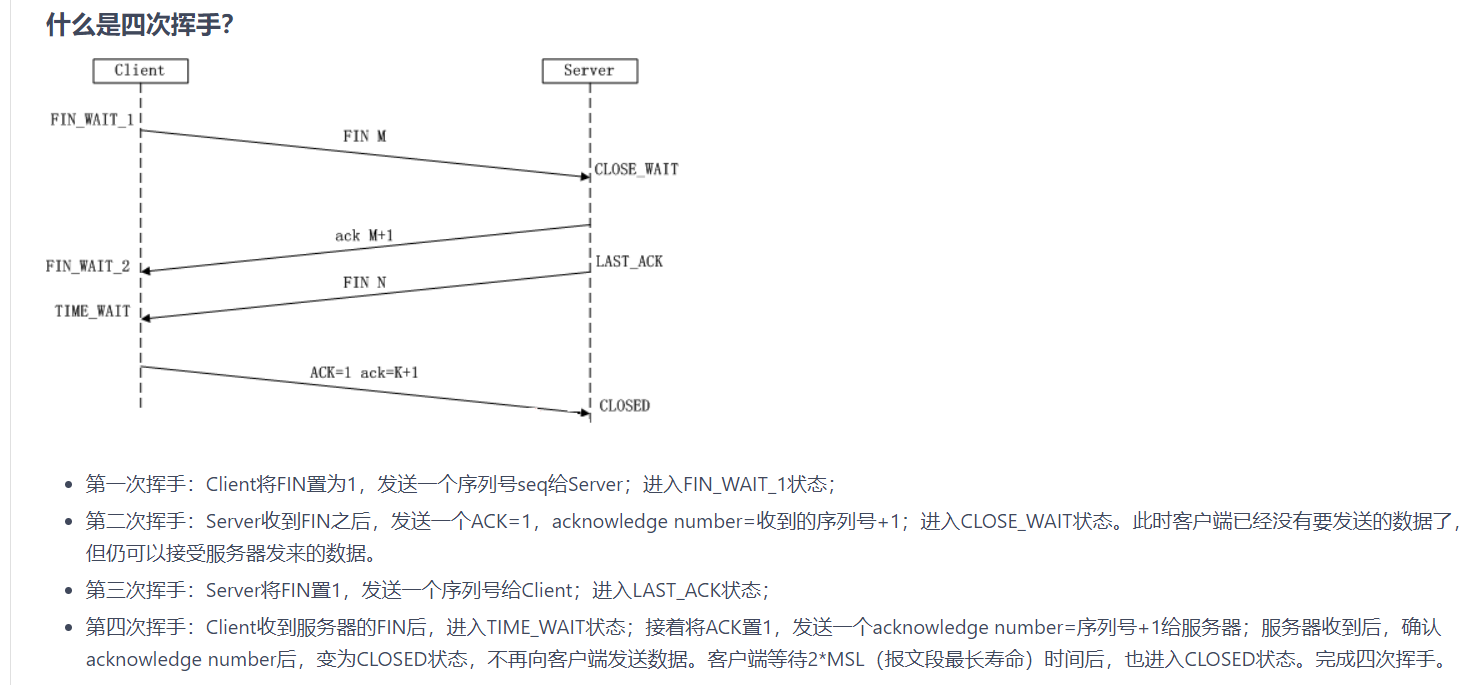
TCP四次挥手
TCP如何实现可靠传输

计算机网络模型

操作系统
进程和线程的区别
| 进程 | 线程 |
|---|---|
| 资源分配基本单位 | 资源调度的基本单位 |
| 有自己的独立地址空间 | 共享所属进程的地址空间 |
| 在进程切换时,涉及存储器管理方面的操作,开销比线程大 | |
| 线程依赖进程而存在 | |
| 进程是拥有系统资源的一个独立单位 | 线程自己基本上不拥有系统资源,只有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈) |
堆和栈的区别
| 堆 | 栈 |
|---|---|
| 由开发者控制 | 编译器自动管理 |
| 堆内存可以达到4G的空间 | 默认的栈空间大小是1-2M |
| 堆频繁new/delete会产生大量碎片(重点是如何解决?如内存池、伙伴系统等) | 不存在碎片问题 |
| 堆向上生长(向着内存地址增加的方向) | 栈向下生长(向着内存地址减小的方向增长) |
| 堆都是动态分配的 | 静态分配和动态分配 |
| 栈是机器系统提供的数据结构,计算机会在底层对栈提供支持,效率更高 |
死锁
多个并发进程中,每个进程持有某种资源又等待其他进程释放它们现在保持着的资源,没改变这个状态之前不能向前推进,这组进程就产生了死锁。
处理方法
鸵鸟策略
- 死锁影响不大,或者概率很低,可以忽略死锁的情况。
死锁预防 (破坏产生死锁的四个条件)
- 破坏互斥:允许某些资源被多个进程同时访问
- 破坏占有并等待:资源预先分配,或者申请资源前先释放占有的资源
- 破坏非抢占:允许强制抢占
- 破坏循环等待条件:对所有资源同一编号,所有进程对资源的请求按序号递增的顺序提出
死锁避免
- 银行家算法:动态检测资源分配状态,处于安全状态才能进行资源分配。(安全状态:即使所有进程突然请求所需的资源,也能存在某种资源分配顺序,让每一个进程运行完毕)
死锁解除
- 利用抢占:挂起进程并抢占其资源(要避免挂起时间过长而饥饿)
- 利用回滚:让某些进程回退到可以解除死锁的情况,自动释放资源
- 杀死某些进程知道死锁解除
死锁的检测
- 检查有向图是否存在环
- 使用类似死锁避免的检测算法
线程是越多越好吗
$最佳线程数 = CPU核心数 (1/CPU利用率) = CPU核心数 (1 + (I/O耗时/CPU耗时))$
算法与数据结构
B树和B+树的区别(B树是一种平衡多路搜索树)
B+树中只有叶子节点会带有指向记录的指针(ROWID),换句话说,就是非叶子节点不会带上 ROWID,一个块中可以容纳更多的索引项,可以降低树的高度;B树所有节点都带有
B+树中所有叶子节点都通过指针连接在一起,范围扫描性能要好一点;B树不会,B树需要在叶子节点和内部节点之间不停地移动。
B树的应用场景
文件系统和数据库
(了解哪些算法)冒泡排序,选择排序,快排
冒泡:比较相邻的元素。升序的话就是,如果第一个比第二个大,就交换位置
选择:最开始在未排序的序列里面找到最小元素,存放到排序序列的起始位置,然后,再从未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推
快排:随机挑一个数作基准,小于基准的放在前,大于基准的放在后。把序列分为较小区和较大区,再分别对小数与大区进行排序。
归并排序:把数据分为两段,从两段中逐个选最小的元素移入新数据段的末尾。可从上到下或从下到上进行。
堆排:从堆顶把根卸出来放在有序区之前,再恢复堆。
双向链表插入节点
http://www.360doc.com/content/17/0427/12/30427643_649056362.shtml

平衡二叉树
任一节点对应的两棵子树的最大高度差为1