[第 1 章] C++的并发世界
1.1 什么是并发?多线程
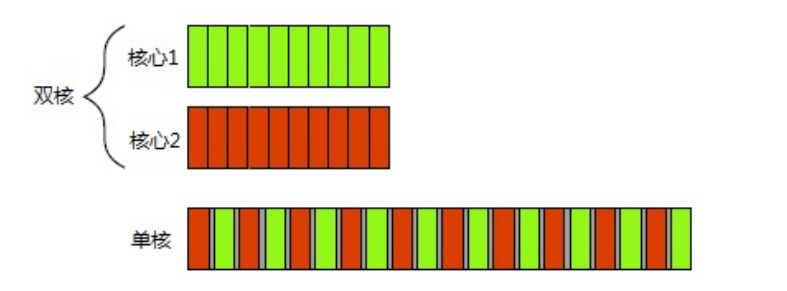
1.1.1 并发的两种方式
- 多核机器的真正并行
- 单核机器的任务切换
1.1.2 并发的两种途径
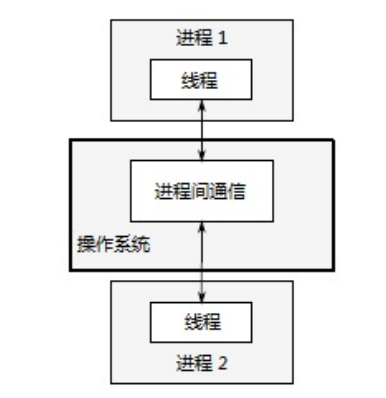
a. 多进程并发
应用程序分为多个独立的进程,它们通过常规的进程间通信传递信息。
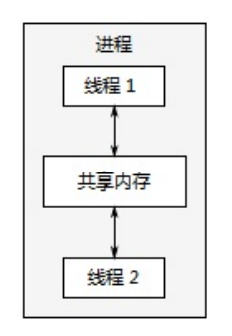
b. 多线程并发
在单个进程中运行多个线程,每个线程相互独立,但共享地址空间,一个进程中的两个线程通过共享内存进行通信。
- 多进程并发与多线程并发的优缺
| 并发途径 | 优 | 缺 |
|---|---|---|
| 多进程并发 | 1. 可远程连接,在不同机器上运行独立的进程 2. 操作系统在进程间提供的附加保护操作和更高级别的通信机制,可以更容易编写出安全的并发代码 |
1. 设置复杂,速度慢 2. 开销大 |
| 多线程并发 | 开销小 | 线程间的数据共享需要确保一致性 |
1.2 为什么要用并发?
- 关注点分离(SOC)
- 性能(任务并行+数据并行)
1.3 什么时候不能用并发?
编写和维护的多线程代码需要一定的成本,额外的复杂性也可能引起更多的错误。
除非性能增益足够大或关注点分离地足够清晰,能抵消开发和维护成本,否则别用并发。
1.4 C++中的多线程
- 管理线程的函数和类在
<thread>中声明 - 每个线程都必须具有一个初始函数
- 新线程启动后,初始线程继续执行,需要
join()确保新线程启动前程序不会结束
1 |
|
[第 2 章] 线程管理
2.1 线程管理基础
2.1.1 启动线程
a. 传入无参数无返回的函数——最简单情况
1 |
|
b. 传入带有函数调用符类型的实例(某个类的对象)
1 |
|
代码中,提供的函数对象会复制到新线程的存储空间中,函数对象的执行和调用都在新线程的内存空间进行。
注意:如果传递一个临时变量,而不是一个命名的变量;C++编译器会将其解析为函数声明,而不是类型对象的定义。比如,以下语句的含义为:声明一个名为 t 的函数,这个函数带有一个参数(函数指针指向没有参数并返回 Test 对象的函数),返回一个 std::thread 对象,而不是启动一个线程。
1 | std::thread t(Test()); |
如何解决上述问题,正确的以
classname()形式启动线程?方法 1,2 均可
1 |
|
2.1.2 等待线程
如果需要等待线程,相关的
std::thread实例需要使用join()。使用
join()而不是detach()可以确保局部变量在线程完成后,才被销毁。- 调用
join()的行为会清理线程相关的存储部分。这样std::thread对象将不再与已经完成的线程有任何关联。也就是说,只能对一个线程使用一次join(),使用过的std::thread对象就不能在加入了。
2.1.3 特殊情况的等待
a. 在异常处理过程中调用join()
避免应用被抛出的异常所终止
1 | struct func |
b. 使用RAII等待线程完成
RAII:Resource Acquisition Is Initialization 资源获取即初始化方式。这里使用 RAII,并且提供一个类,在析构函数中使用 join()
1 | class thread_guard |
线程执行到 4 时,局部对象就要逆序销毁,所以 g 被第一个销毁,这时线程在析构函数中被加入到原始线程中,即使 do_something_in_current_thread 抛出一个异常,这个销毁依旧会发生。
拷贝构造函数和拷贝赋值操作被标记为 =delete,是为了不让编译器自动生成它们。通过删除声明,任何尝试给 thread_guard 对象赋值的操作都会引发一个编译错误。
2.1.4 后台运行线程
detach() 会让线程在后台运行(主线程不能与之产生直接交互)。 如果线程分离,就不可能有 std::thread 对象能引用它,相应的 std::thread 对象就与实际执行的线程无关了,并且这个线程也无法进行加入。
1 | std::thread t(do_background_work); |
通常分离线程被称为守护线程,UNIX中指的守护线程是指,没有任何用户接口,并在后台运行的线程。
从std::thread对象中分离线程的前提
要存在可进行分离的线程。不能对没有执行线程的 std::thread 对象使用 detach(),当然这也是 join() 的使用条件,并且要用同样的方式进行检查——当 std::thread 对象使用 t.joinable() 返回的是 true,就可以使用 t.detach()
- 示例(使用分离线程去处理其他文档)
1 | void edit_document(std::string const& filename) |
代码逻辑:如果用户打开一个新文档,为了更快的打开文档,需要启动一个新线程去打开新文档$^{1}$,并分离线程$^{2}$。
2.2 向线程函数传递参数
注意:默认参数要拷贝到线程独立内存中,即使参数是引用的形式,也可以在新线程中进行访问。
1 | void f(int i, std::string const& s); |
提供的参数可以移动(move)但不能拷贝(copy)
move:原始对象中的数据转移给另一个对象,原始对象不在保存这些数据,相当于剪切了
2.3 转移线程所有权
std::thread 可转移(move)但不可拷贝(copy)。
1 | void some_function(); |
因此,不能将执行某个函数的线程的所有权转移给一个已经关联某个线程的实例(如第 8 行)
2.4 运行时决定线程数量
1 | // 返回能同时并发在一个程序中的线程数量 |
a. 并行版的 std::accumulate
代码中将整体工作拆分成小任务交给每个线程去做,其中设置最小任务数,是为了避免产生太多的线程。程序可能会在操作数量为0的时候抛出异常。比如,std::thread 构造函数无法启动一个执行线程,就会抛出一个异常。
1 | template<typename Iterator,typename T> |
2.5 识别线程
线程标识类型为 std::thread::id,可通过两种方式获得
std::thread对象的成员函数get_id()直接获取- 在当前线程中调用
std::this_thread::get_id()(该函数定义在<thread>头文件中)
[第 3 章] 线程中共享数据
3.1 共享数据可能存在什么问题?
如果数据只读,就不会有什么问题。但是如果有线程可以修改数据,就可能导致不变量被修改。就比如双向链表正在删除一个节点:(总的来说就是,在修改数据的同时,有线程在访问这个被修改的数据)
如果这个时候正好有线程访问刚刚删除一边的节点(正好删除了左右指针中的一个),这样的话,线程就读取到了要删除的这个节点的数据。
如果该节点的左指针先被删除,有一个线程从左到右访问链表,就会跳过这个待删除的节点;如果有第二个线程尝试删除图中右边的节点,程序就会崩溃。这就是条件竞争
3.1.1 条件竞争
并发中竞争条件的形成,取决于线程的相对执行顺序。上述共享数据的问题就是恶性条件竞争
a. 如何避免恶性条件竞争
对数据结构采用某些保护机制。(确保只有进行修改的线程才能看到不变量被破坏时的中间状态;其他线程角度来看,要么修改还没开始,要么已经结束)
无锁编程(lock-free programming)
使用事务的方式去处理数据结构的更新。
数据和读取都存储在事务日志中,然后将之前的操作合为一步,再进行提交。如果数据结构正在被某个线程修改就无法提交。
保护共享数据结构的最基本的方式,是使用C++标准库提供的互斥量(mutex)。
3.2 使用互斥量保护共享数据
- 如何在多线程程序中,使用
std::mutex构造的std::lock_guard实例,创建互斥量,通过调用成员函数lock()上锁,unlock()解锁,从而对一个列表进行访问保护。
1 |
|
上述代码的标注$^{3}$和标注$^{4}$,使用 std::lock_guard<std::mutex> 使这两个函数对数据的访问是互斥的。(list_contains 不可能看到正在被 add_to_list 修改的列表)。
其实大多数的情况是这样的:互斥量和要保护的数据放在同一个类,这时,上述的两个函数都作为类的成员函数, 互斥量和要保护的数据都要定义成 private 成员。
3.2.1 在成员函数中加入 std::lock_guard 一定可以保护数据吗?
不一定。可能存在迷失指针或引用。
如何避免这样的问题?
在确保成员函数不会传出指针或引用的同时,检查成员函数是否通过指针或引用的方式来调用也是很重要。
只要成员函数的返回值或者输出参数没有指向被保护数据的指针或引用,数据就是安全的。
如果用 std::lock_guard 保护数据,但在同一个函数中,又将保护数据传给某个用户提供的函数,就麻烦了,因为这个函数可能是恶意的,能绕过保护机制。
3.2.2 死锁
一个给定操作需要两个或两个以上的互斥量时,可能会出现死锁(deadlock)。
死锁与条件竞争相反,不同的两个线程会互相等待,导致什么都没做。
a. 如何避免死锁?
死锁一般建议:让两个互斥量总以相同的顺序上锁。
但这只适用于互斥量用于不同的地方的时候;如果不同互斥量保护同一个类的实例时,比如实例提供的第一互斥量作为第一个参数,提供的第二个互斥量为第二个参数,在参数交换了之后,两个线程试图在相同的两个实例间进行数据交换时,程序 又死锁了!
C++中解决这个问题的方法
std::lock可以一次性锁住多个(两个以上)的互斥量,且没有死锁风险
1 | // 在一个简单的交换操作中使用 std::lock |
标注$^{1}$锁住两个互斥量,标注$^{2,3}$表示两个 std:lock_guard 实例已经创建好,提供 std::adopt_lock参数除了表示 std::lock_guard 对象已经上锁外,还表示现成的锁,而非尝试创建新的锁。
b. 避免死锁的进阶
- 避免嵌套锁
- 避免在持有锁的时候,调用用户提供的代码
- 使用固定顺序获取锁
- 使用锁的层次结构