第一部分 简介
第一章 温故而知新
硬件结构相关
- 计算机的核心: CPU,内存,I/O控制芯片
- 北桥芯片 (PCI Bridge) 协调高速设备 连接CPU,内存,PCI总线
南桥芯片 (ISA Bridge) 专门处理低速设备,汇总后连接到北桥
SMP与多核
- 对称多处理器(SMP,Symmetrical Mutil-Processing): 每个CPU在系统中的地位和功能一样,是相互对称的。理想情况下,速度的提高与CPU数量成正比,但实际上不能。因为不是所有的程序都能分解成若干个完全不相关的子问题。
- 多核处理器 实际上就是SMP的简化版
计算机软件体系结构

接口的上层:使用者
接口的下层:提供者
操作系统的功能
在CSAPP中也有提到,这里更加简练
- 提供抽象的接口
- 管理硬件资源
虚拟地址空间
简单的内存分配策略存在问题:
- 地址空间不隔离
- 内存使用效率低
- 程序运行的地址不确定
所以用一种间接的地址访问方法:虚拟地址
目的: 保证程序能访问的物理内存区域与另外的程序不重叠(也即 地址空间隔离)
原始方法:分段
最开始采用分段的方法: 将一段程序所需的内存空间大小的虚拟空间映射到某个地址空间。
优点: 隔离地址空间+确定程序运行的地址
缺点: 没解决内存使用效率低的问题
分页
方法:将地址空间分为固定大小的页(页大小由操作系统决定)
包括:虚拟页(VP),物理页(PP),磁盘页(DP)
可以看到下图中,虚拟空间有些页被映射到同一个物理页,这样就可以实现内存共享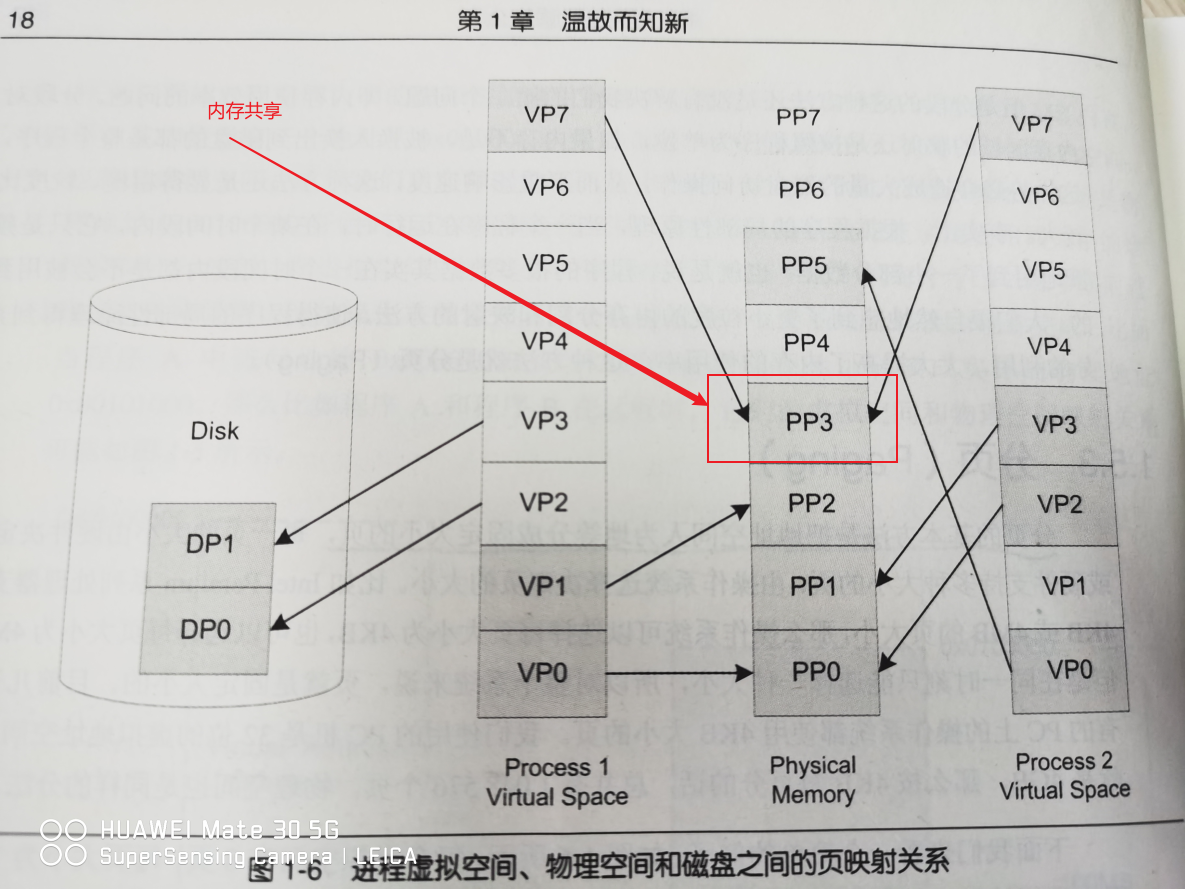
页映射: 采用MMU (Memory Management Unit)进行页映射。页映射模式下,CPU发出的是虚拟地址,经过MMU转换后变成物理地址,一般MMU都集成在CPU内部了,不会以独立的部件存在
线程
组成: 线程=线程ID+当前指令指针PC+寄存器集合+堆栈
进程内的各个线程之间共享程序的内存空间和一些进程级的资源
线程的访问权限
线程的私有存储空间包括:栈、线程局部存储、寄存器
I/O密集型线程: 频繁等待
CPU密集型: 很少等待
抢占的概念:线程在用尽时间片之后会被强制剥夺继续执行的权利,进入就绪状态,这个过程就是抢占。即之后执行的别的线程抢占了当前线程
可抢占线程: 用尽时间片后被剥夺权利
不可抢占线程: 线程必须手动发出放弃执行的命令或者试图等待某事件,才能让其他线程得到执行
Linux的多线程
Linux将所有的执行实体(无论线程、进程)都成为任务(Task),任务在概念上类似于一个单线程的进程。不过Linux下不同的任务之间可以选择共享内存空间,所以实际上,共享了同一个内存空间的多个任务构成了一个进程,这些任务就是这个进程里的线程。
Linux创建新任务的方法

fork产生新任务的速度很快,因为并不复制原任务的内存空间,而是和原任务一起共享一个写时复制 (Copy on Write, COW)
写时复制: 两个任务可同时自由读取内存,当任意一个任务试图修改内存时,内存就会复制一份提供给修改方单独使用,以免影响到其他任务的使用
线程安全:同步与锁
单指令操作(原子操作)不会被打断
同步
在一个线程访问数据未结束时,其他线程不得访问同一数据,同步最常见的方法就是使用锁
锁
是一种非强制机制,每个线程在访问数据前首先试图获取锁,并在访问结束后释放。锁已被占用时,线程会等待其重新可用
- 二元信号量: 延申:(多元)信号量
- 互斥量: 信号量可以被一个线程获取再由其他线程释放,但互斥量要求释放者必须是获取者
- 临界区: 比互斥量更严格,对于一个进程创建的互斥量和信号量,另一个进程去获取该锁也是合法的。而临界区将作用范围限制在本进程。
- 读写锁: 有两种获取:共享方式和独占方式


三种线程模型
一对一模型
一个用户使用的线程就唯一对应一个内核使用的线程(反过来就不一定,因为一个内核里的线程在用户态不一定有对应的线程存在)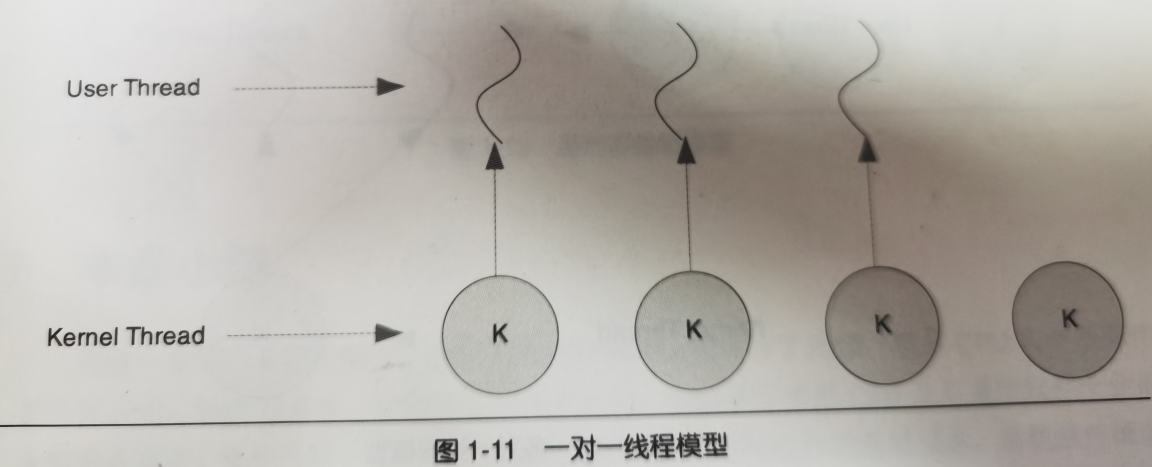
优点: 一个线程阻塞,其他线程不受影响
缺点:
- 许多操作系统限制了内核线程的数量,一对一线程使用户线程数量也受到限制
- 许多操作系统内核线程调度时,上下文切换的开销大,导致用户线程执行效率下降
多对一模型
多个用户线程映射到一个内核线程,线程之间的切换由用户态的代码进行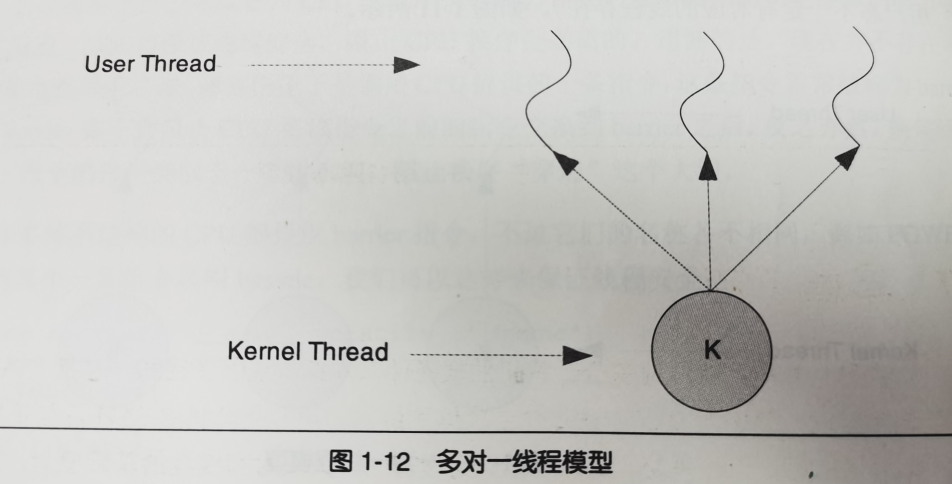
优点:
- 上下文切换更高效
- 线程数量几乎无限制
缺点: 一个用户线程阻塞,其他所有线程都无法执行
多对多模型
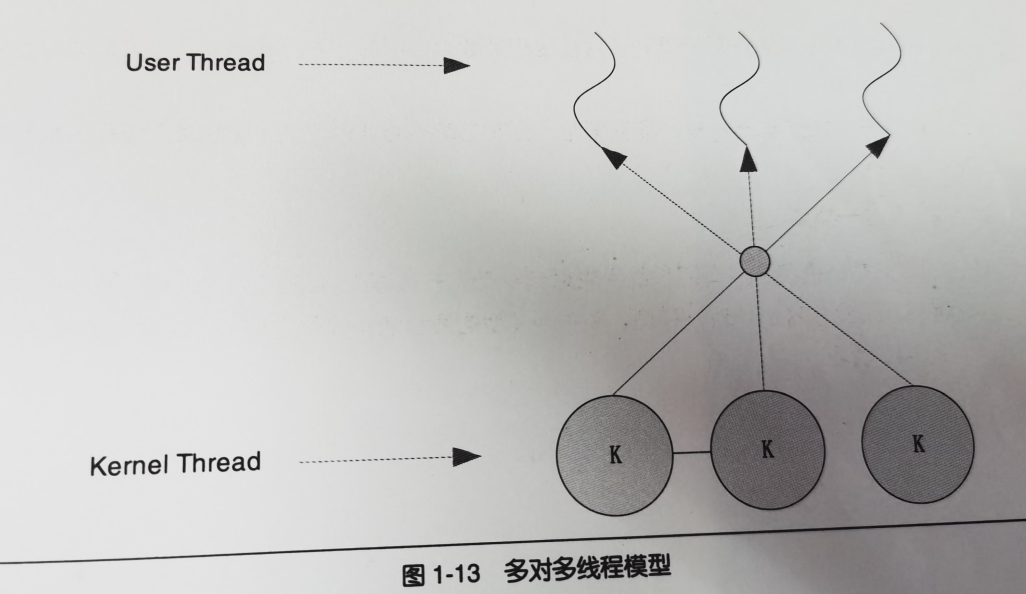
优点:
- 一个用户线程阻塞不会使所有用户线程阻塞
- 用户线程数量也没什么限制
第二部分 静态链接
第二章 编译和链接
构建: 编译和链接合并到一起的过程
被隐藏的过程
又是熟悉的代码
1 | #include <stdio.h> |
预编译
说明: 对于C程序,会被预编译成.i文件;对于C++程序,预编译成.ii文件
命令: 对于hello.c文件gcc -E hello.c -o hello.i
或者cpp hello.c > hello.i
处理规则:
- 删除所有
#define并展开所有宏定义 - 处理所有条件预编译指令,如
#if#ifdef#elif#else#endif - 递归处理
#include - 删除所有注释
- 添加行号、文件标识符
- 保留所有
#pragma编译器指令
经过预编译后的.i文件不包含任何宏定义,因为所有宏定义都被展开,并且包含的文件也被插入到.i文件。
所以当无法判断宏定义是否正确或者头文件包含是否正确时,可查看预编译后的文件确定问题。
编译
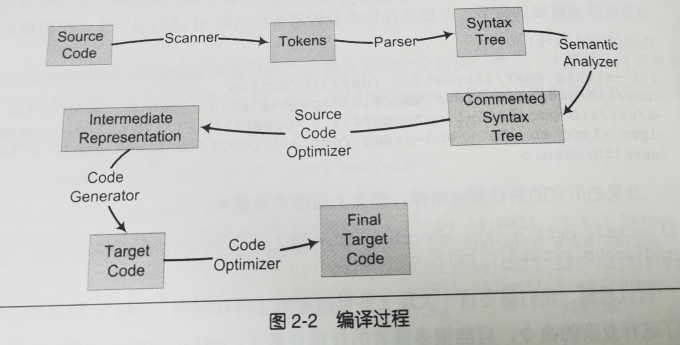
过程说明: 扫描、语法分析、语义分析、源代码优化、代码生成、目标代码优化
命令:gcc -S hello.i -o hello.s
或者gcc -S hello.c -o hello.s
- 词法分析: 首先源代码程序被输入到扫描器,运用一种类似有限状态机的算法将源代码的字符序列分割成一系列记号。
- 语法分析: 采用上下文无关语法对记号进行语法分析,生成以表达式为节点的语法树。
- 语义分析: 生成标识语义的语法树。编译器能分析的是静态语义,在编译期间可以确定(比如将浮点型赋值给一个指针);动态语义只有在运行期间才能确定。(比如0作为除数)
- 中间语言生成: 直接在语法树上优化比较困难,所以源代码优化器(Source Code Optimizer)往往将整个语法树转换成中间代码。它是语法树的顺序表示,非常接近目标代码。
中间代码使编译器可分为前后端。前端负责产生机器无关的中间代码,后端将中间代码转换成目标机器代码
- 目标代码生成与优化: 代码生成器依赖目标机器将中间代码转成目标机器代码,代码优化器负责对目标机器代码进行优化(如选择合适的寻址方式)
汇编
说明: 根据汇编指令和机器指令的对照表一一翻译
命令:as hello.s -o hello.o
或者gcc -c hello.s -o hello.o
或者gcc -c hello.c -o hello.o
链接
C/C++模块之间通信方式:
- 模块间的函数调用
- 模块间的变量访问
这两种方式可以归结为一种:模块间符号的引用。而模块的拼接过程就是链接
过程: 地址和空间分配、符号决议(确保所有目标文件中的符号引用都有唯一的定义)、重定位
最基本的静态链接过程:每个模块的源码文件.c经过编译器编译成目标文件.o,目标文件和库(最常见的是运行时库Runtime Library)一起链接成可执行文件
第三章 目标文件里有什么
目标文件的格式
PE和ELF都是COFF的变种,COFF的主要贡献:在目标文件中引入段机制+定义了调试数据的格式。
按照可执行文件存储的文件有:可执行文件、动态链接库(如Windows的DLL和Linux的so)、静态链接库(如Windows的.lib和Linux的.a)
ELF文件标准里,将系统中采用ELF格式的文件归为4类
目标文件是什么样的
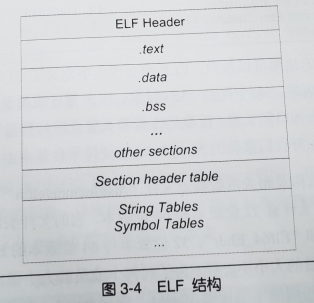
说明
- 源代码编译后的机器指令存放在代码段.text或者.code
- 初始化的全局变量或局部静态变量存放在数据段.data
- 未初始化的变量存放在BSS段,准确地说是.bss段为它们预留了空间。(注意:初始化为0的可以被认为是未初始化的,被优化掉放在.bss可以节省磁盘空间,因为.bss不占磁盘空间)
- 除了以上三个基本的段以外,还有只读数据段.rodata,注释信息段.comment,堆栈提示段.note.GNU-stack
指令操作
gcc -c simple.c-c表示只编译,不链接objdump -h simple.oobjdump查看目标文件结构及内容,-h就是把ELF文件的各个段基本信息打印出来,-x可以打印更多的信息size simple.o可以查看ELF文件代码段、数据段、BSS段的长度objdump -s -d simple.o-s可以将所有段的内容以16进制打印,-d将所有包含指令的段反汇编
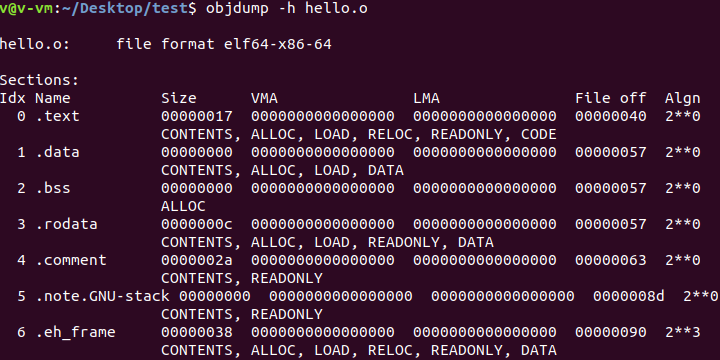
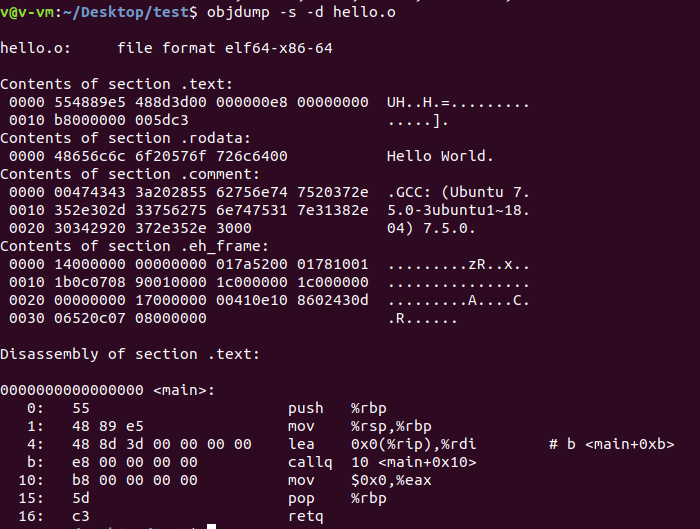
其他段
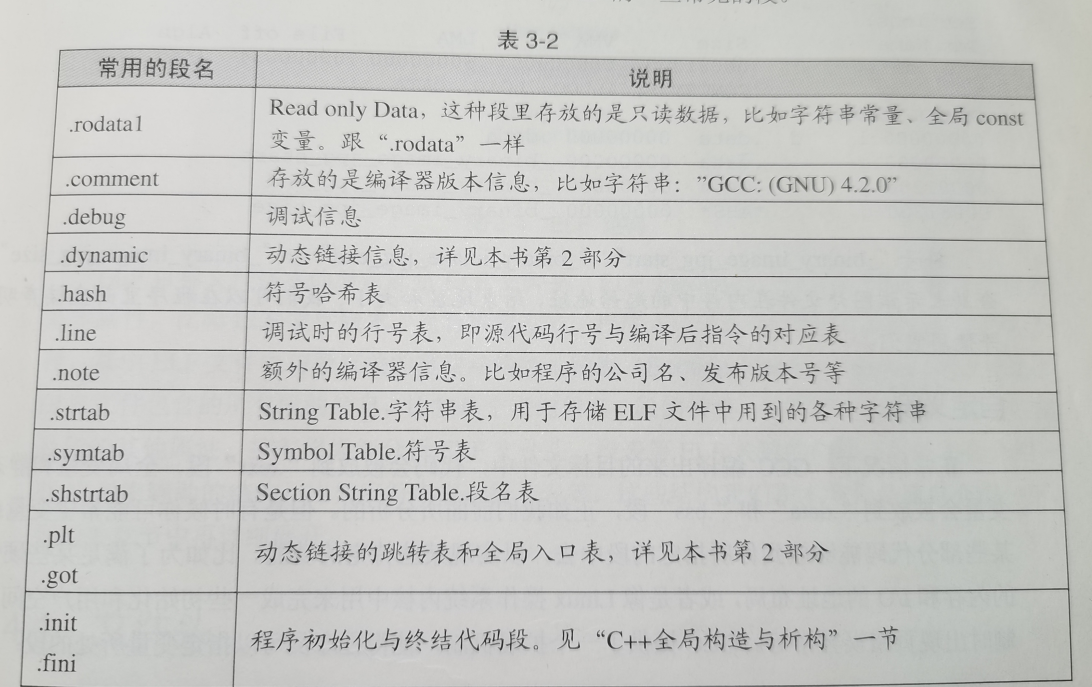
ELF文件结构
还是这张图
文件头
描述了文件基本属性,包括ELF文件版本、目标机器型号、程序入口地址等
命令: readelf -h simple.o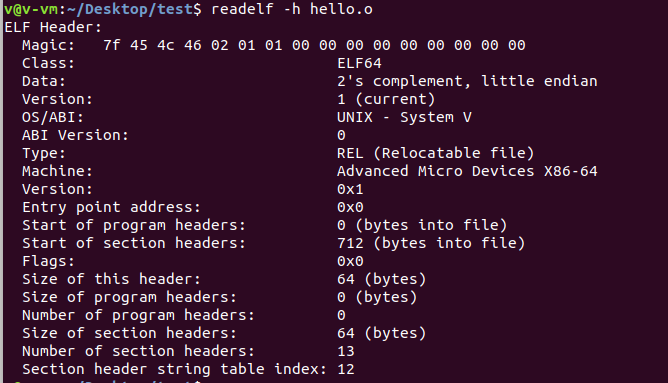
可以看到,ELF文件头中定义了:ELF魔数、文件机器字节长度、数据存储方式、版本、运行平台、ABI版本、ELF重定位类型、硬件平台、硬件平台版本、入口地址、程序头入口和长度、段表位置和长度、段的数量等。
ELF有32位和64位版本,它们的文件头内容是一样的,只不过有些成员的大小不一样。ELF文件头结构及相关常数被定义在/usr/include/elf.h ,其中自定义了一些类型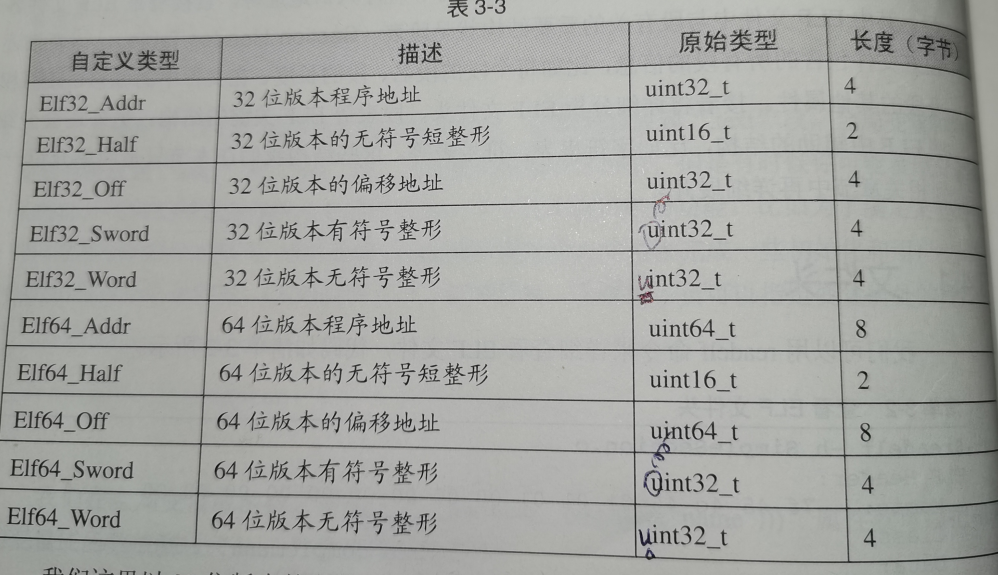
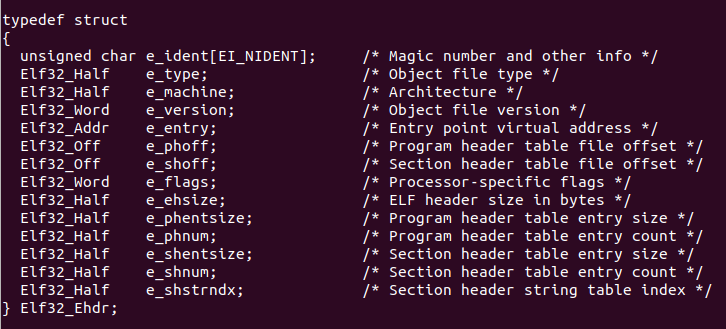
Elf32_Ehdr结构体中定义的成员含义为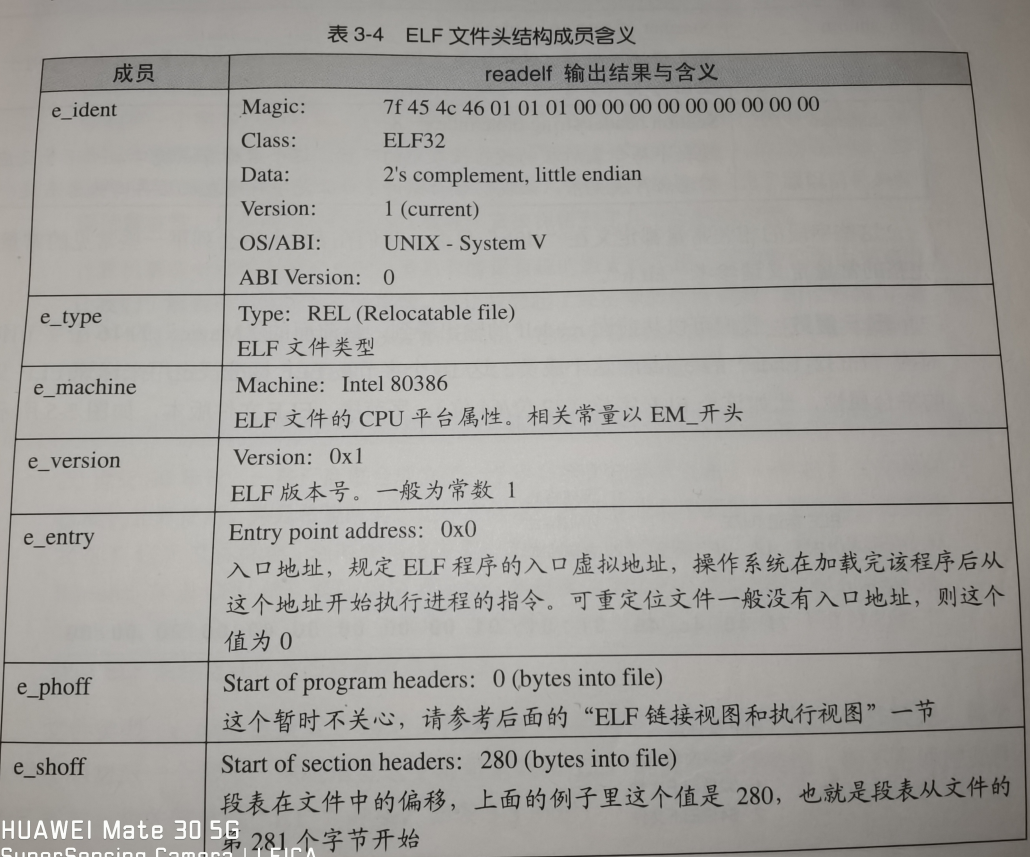

ELF魔数
前四个字节是所有ELF文件都必须相同的标识码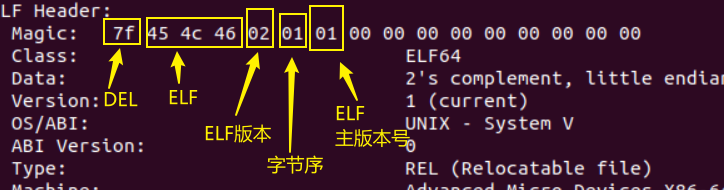
字节序和ELF版本的规定

文件类型

etype成员表示ELF文件类型,每个文件类型对应一个常量,系统通过这个常量来判断ELF的真正文件类型,而不是通过扩展名。相关常量以“EL”开头
段表
段表位置由ELF文件头中的e_shoff决定,这里的712是十进制
查看命令: readelf -S hello.o(注意objdump会省略辅助性的段,readelf查看的才是真正的段结构)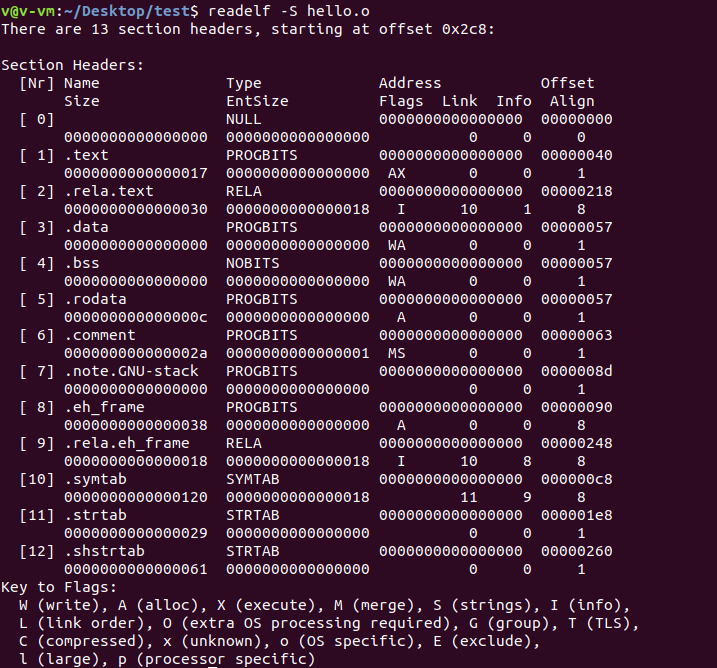
段描述符Elf32_Shdr
段表的结构是一个以Elf32_Shdr结构体为元素的数组,对于以上hello.o就是有13个元素的数组。其中第一个元素是无效的,所以共有12个有效的段
Elf32_Shdr的结构同样在/usr/include/elf.h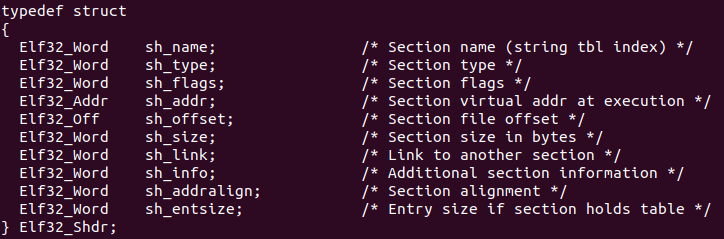
各个成员的含义
链接的接口——符号
在链接中,将函数和变量统称为符号,函数名和变量名就是符号名。每个目标文件都有一个响应的符号表,每个符号有对应的符号值,对于变量和函数来说,符号值就是它们的地址。nm hello.o可以查看ELF文件的符号表readelf -s hello.o可以查看更详细额符号信息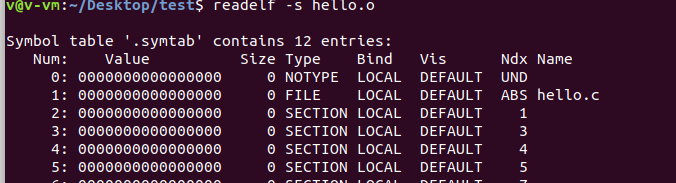
其中,Value为符号值(函数相对于代码段起始位置的偏移量),Size为符号大小(函数指令所占的字节数),Type和Bind为符号类型和绑定信息,Ndx为符号所在段。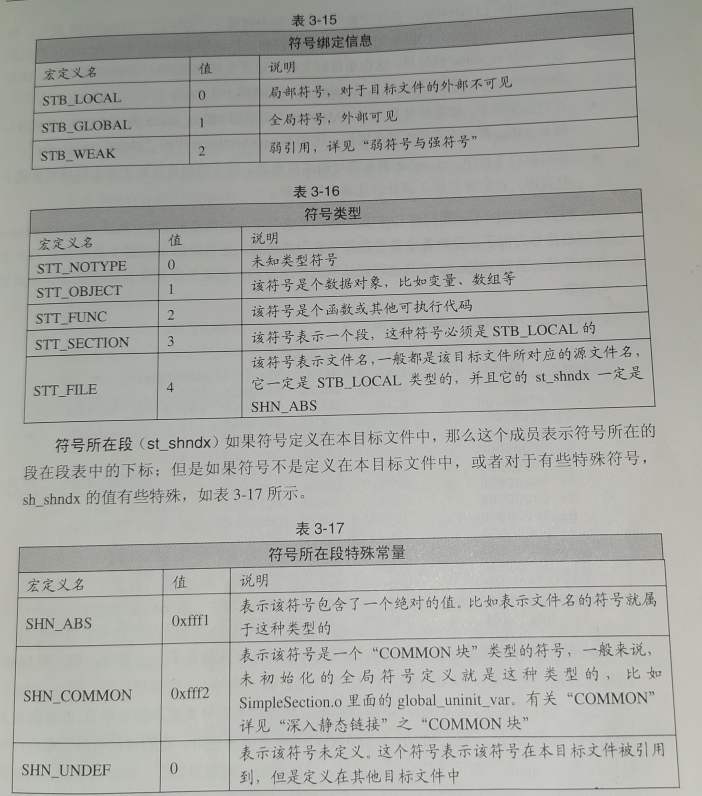
C++符号修饰
区别重载的函数+防止静态变量冲突
extern “C”
Linux版本的gcc对extern “C”里面的符号不做修饰,可以利用声明一个与CPP中某些符号修饰结果相同的外部符号,直接获取其对应的值
第四章 静态链接
空间地址分配
我们输入多个目标文件,链接器怎么将它们的各个段合并到输出文件?或者说,输出文件中的空间如何分配给输入文件?
按序叠加
存在的问题:输出文件会有很多零散的段,造成内存空间大量的内存碎片。
相似段合并
问:这里的空间分配是指什么空间?
答:虚拟地址空间的分配
链接器空间分配的基本策略: (两步链接)
- 空间与地址分配
- 符号解析与重定位 (核心)
命令:
ld a.o b.o -e main -o ab-e表示将main作为程序入口,ld默认入口为_start,-o ab表示链接输出文件名为ab,默认为a.outobjdump -h filename可查看链接前后地址的分配情况
VMA: Virtual Memory Address虚拟地址
确定符号地址
链接器进行空间地址分配后,各个段的虚拟地址就确定了,链接器开始计算每个符号的虚拟地址。
重定位表
如果.text有要被重定位的地方,会有一个相对应的.rel.text;如果.data又要被重定位的地方,就会有一个.re.data保存数据段的重定位表。每个要被重定位的地方叫一个重定位入口objdump -r a.o 查看目标文件的重定位表
符号解析
重定位过程中,每个重定位入口都是对一个符号的引用,当链接器需要对某个符号的引用进行重定位时,它就要确定这个符号的目标地址。链接器就会查找所有输入目标文件的符号表组成的全局符号表,找到对应的符号后进行重定位。
指令修正方式
对于32位x86平台下的ELF文件的重定位入口所修正的指令寻址方式只有两种:绝对近址32位寻址、相对近址32位寻址。
区别:绝对寻址修正后的地址为该符号的实际地址,相对寻址修正后的地址是符号距离被修正位置的地址差。
COMMON块
拓展:这种机制最早来源于Fortran,早期Fortran没有动态分配空间的机制,程序员必须声明它所需要的临时使用空间的大小。这种空间就是COMMON块,当不同的目标文件需要的COMMON块大小不一致时,以最大的那块为准。COMMON块可以应对一个弱符号定义在多个目标文件中,而它们类型又不同的情况。
一旦一个未初始化的全局变量不是以COMMON块的形式存在时,那么它就相当于一个强符号,如果其他目标文件中还有同一个变量的强符号定义,链接时就会发生符号重复定义的错误。
C++问题
- 重复代码消除
- 全局构造与析构
重复代码消除
模板、外部内联函数、虚函数表都有可能在不同的编译单元里产生相同的代码
方法:将每个模板的实例代码都单独存放到一个段里,每个段只包含一个模板实例。但是相同名称的段可能拥有不同的内容,导致编译出来的实际代码有所不同,这种情况,链接器随意选择一个副本作为链接的输入。
函数级别链接: 让所有函数像上文提到的模板函数那样单独保存到一个段,链接器需要某个函数就合并到输出文件,对于没有用的函数则抛弃。
全局构造与析构
全局对象的构造函数在main函数之前被执行,全局对象的析构函数在main之后执行
ELF文件两个特殊的段:.init(进程的初始化代码,main以前执行)和.fini(进程终止代码指令,main以后执行)
静态链接库
- 列举静态库文件libc.a中的目标文件
ar -t libc.a - 找到printf所在的目标文件
objdump -t libc.a
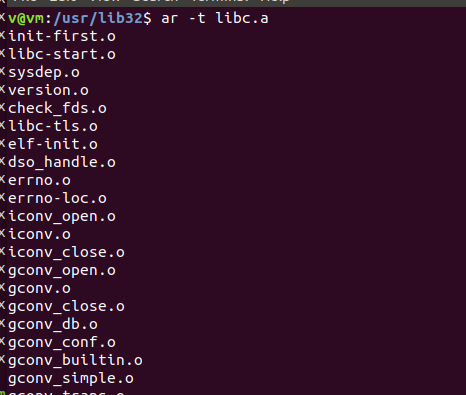
gcc -c -fno-builtin hello.c -fno-builtin 关闭内置函数优化gcc -static --verbose -fno-builtin hello.c -verbose 将编译链接的中间步骤打印出来
问:为什么静态运行库里一个目标文件只包含一个函数?
答:如果很多函数放在一个目标文件中,很多没用的函数也会被链接到输出结果中,造成空间的浪费。
链接过程控制
Windows操作系统内核:C:\Windows\System32\ntoskrnl.exe
连接控制脚本
ld -verbose 查看ld默认的链接脚本ld -T link.script 指定自己写的脚本为链接控制脚本
第五章 Windows PE/COFF
PE/COFF文件与ELF文件非常相似,它们都是基于段的结构的二进制文件格式。Windows下最常见的目标文件格式就是COFF格式。
COFF文件有一个.drectve段,其中保存编译器传递给链接器的命令行参数,可以通过这个段实现指定运行库等功能。
Windows下的可执行文件、动态链接库等都使用PE文件格式,PE文件格式是COFF文件格式的改进版本,增加了PE文件头、数据目录等结构。
第三部分 装载与动态链接
第六章 可执行文件的装载与进程
进程与程序的区别
程序是一个静态的概念,就是一些预先编译好的指令和数据集合的一个文件;进程是一个动态的概念,是程序运行时的一个过程。
程序像菜谱,进程像做菜的过程。
PAE (Physical Address Extension)
32位的CPU,程序使用的虚拟地址空间不能超过4GB;计算机的内存空间是可以超过的,通过PAE可以完成。
应用程序如何使用这些大于常规的内存空间?
窗口映射:把额外的内存映射到进程地址空间。
举例:比如32位CPU,有一个应用程序用一段256MB的虚拟地址空间做窗口,程序可以从高于4GB的物理空间中申请多个256MB的物理空间,编号成ABC,然后根据需要将窗口映射到不同的物理空间块,用到A的时候就把窗口映射到A,用到B就映射过去,如此重复。
Windows下这种访问内存的操作是AWE(Address Windowing Extension);
Linux下采用mmap()系统调用实现。
装载的方式
静态装载方法:将程序运行所需要的指令和数据全都装入内存。
动态装入:将程序最常用的部分留在内存,不太常用的部分存在磁盘。这样可以更有效的利用内存
典型的动态装载方法:覆盖装入(Overlay)和页映射(Paging)。原则上都是利用了程序的局部性原理。
覆盖装入已经几乎被淘汰了,其基本原理就是将有依赖关系的A和B内存覆盖,形成共享块内存区域,调用谁,覆盖管理器就把谁读入内存。
页映射是将内存和所有磁盘中的数据和指令按照页为单位进行划分,以后装在和操作的单位就是页。
进程的建立
- 创建一个虚拟地址空间: 虚拟空间由一组页映射函数将虚拟空间的各个页映射到响应的物理空间,所以创建虚拟空间实际上不是创建空间,而是创建映射函数所需要的数据结构。
- 读取可执行文件头,建立虚拟空间与可执行文件的映射关系
- 将CPU指令寄存器设置成可执行文件入口,启动运行: 可以认为操作系统执行了一条跳转指令,直接跳转到可执行文件的入口地址。(ELF文件头保存有入口地址)
section 和 segment
从链接的角度看,ELF文件按Section存储
从装载的角度看,ELF文件按Segment划分
ELF可执行文件和共享库文件有程序头表专门保存Segment。而ELF目标文件由于不需要装载,所以没有程序头表。
堆和栈
堆和栈在进程的虚拟空间中也是以VMA(Virtual Memory Area虚拟内存区域)的形式存在
进程虚拟地址空间小结
- 操作系统通过给进程空间划分出一个个VMA来管理进程的虚拟空间
- 基本原则是将相同权限属性的、有相同影像文件的映射成一个VMA
- 一个进程基本上可以分成4中VMA
堆的最大申请数量
- 测试 malloc 最大内存申请量
1 |
|
- 在我的 Linux 环境(64 位的虚拟机环境)下,结果大约是 2.8 GB

- 在我的 Windows 环境(64 位)下,结果大约是 1.8 GB
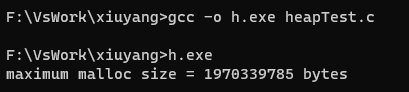
- 影响 malloc 最大内存申请量的因素
- 操作系统版本
- 程序本身大小
- 用到的动态/共享库数量、大小
- 程序栈数量、大小
Linux 内核装载 ELF 的过程
1 用户层面
- bash 进程调用
fork()创建一个新的进程 - 新的进程调用
execve()执行指定 ELF
2 内核层面
进入 execve() 系统调用后
- 内核中
execve()入口是sys_execve(),sys_execve()进行一些参数的检查复制后,调用do_execve() do_execve()查找被执行的文件,并读取文件的前 128 个字节,判断文件格式。然后调用search_binary_handle()搜索合适的装载处理过程。- 针对 ELF 的装载处理过程是
load_elf_binary() - 装载处理完成后,返回至
do_execve()再执行返回至sys_execve(),随即从内核态返回到用户态,EIP 寄存器直接跳转到 ELF 程序入口地址,新的程序开始执行,ELF 文件装载完成。
Windows PE 的装载
- 读取文件的第一个页(其中包含 DOS 头,PE 文件头和段表)
- 检查进程地址空间中,目标地址是否可用,不可用则另选一个装载地址(针对 DLL)
- 使用段表提供的信息,将 PE 文件中所有的段一一映射到地址空间中相应的位置
- 如果装载地址不是目标地址,则 Rebasing
- 装载所有需要的 DLL
- 将 PE 文件中所有导入的符号进行符号解析
- 根据 PE 头中指定的参数,建立初始化栈和堆
- 建立主线程并启动进程
第九章 Windows 下的动态链接
9.1 DLL 简介
DLL 即动态链接库 Dynamic-Link Library。
- DLL 与 ELF 的区别:ELF 中代码段是地址无关的,可以实现进程间共享一份代码;DLL 的代码不是地址无关的,只能在某些情况下可以被多个进程共享
9.1.1 如何创建DLL
- MSVC 编译器工具路径 C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.27.29110\bin\Hostx64\x64,可以在开始菜单进入 Command Prompt 使用 cl
- Math.c 示例代码
1 | __declspec(dllexport) double Add(double a, double b) |
cl /LDd Math.c生成 Debug 版的 DLL(/LD 是 Release 版的 DLL)
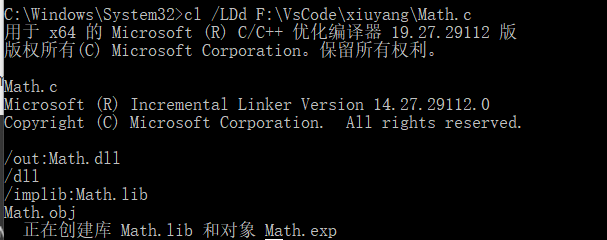
- 生成的 4 个文件默认输出到 C:\Windows\System32,其中 Math.dll 就是我们需要的文件
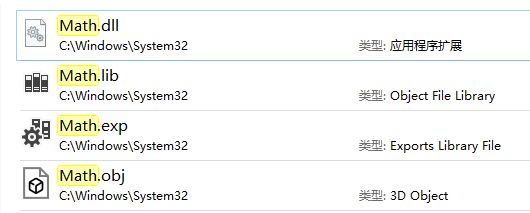
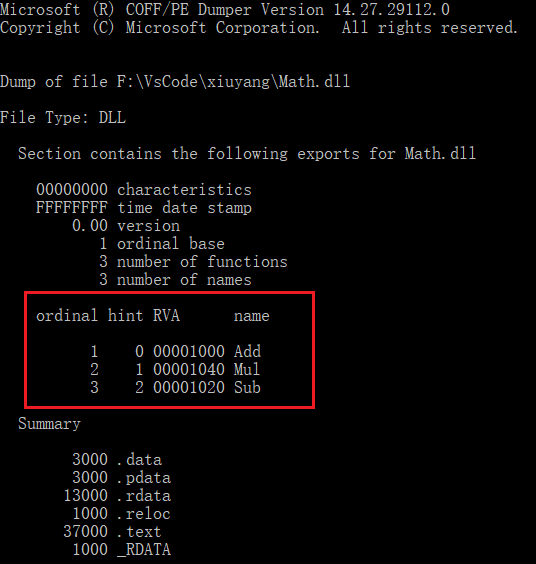
dumpbin /EXPORTS Math.dll(dumpbin 工具和 cl 在同一目录)查看 DLL 的导出符号
9.1.2 如何使用 DLL
a. 静态链接(dllimport 导入符号)
__declspec(dllimport)显式声明某个符号为导入符号
1 | #include <stdio.h> |
cl /c TestMath.c将 c 代码编译成 obj,注意 command prompt 输出默认都在 C:\Windows\System32link TestMath.obj Math.lib使用链接器 TestMath.obj 和 Math.lib 链接在一起,生成 TestMath.exe 文件Math.lib 装的是什么:其包含了 TestMath.o 链接 Math.dll 时所需的导入符号以及一部分“桩”代码(“胶水”代码),以便于将程序和 DLL 粘在一起。这样的 lib 文件又被称为导入库(Import Library)
在命令行运行该文件,可以正常输出结果

b. 运行时链接(LoadLibrary 运行时加载)
- LoadLibrary 装载一个 DLL 到进程的地址空间
GetProcAddress 查找某个符号的地址
FreeLibrary 卸载已装载的模块
- 示例代码:runtimeLink.c
1 | #include <windows.h> |
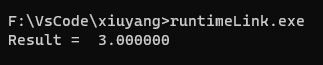
- 编译:
cl runtimeLink.c,得到 runtimeLink.exe ,在命令行运行结果如下。成功调用了 Math.dll 中的 Add 函数
9.2 符号导入导出表
9.2.1 导出表
a. 什么是导出表
导出表集中了所有导出的符号,提供了符号名与符号地址的映射。
- 路径:C:\Program Files (x86)\Windows Kits\10\Include\10.0.18362.0\um\winnt.h
导出表就是其中的 _IMAGE_EXPORT_DIRECTORY 结构体
最后三个成员指向三个重要数组,分别是 导出地址表(EAT,Export Address Table),符号名表(Name Table)和名字序号对应表(Name-Ordinal Table)
1 | typedef struct _IMAGE_EXPORT_DIRECTORY { |
b. 怎么查看可以导出的函数
dumpbin /DIRECTIVES Math.obj
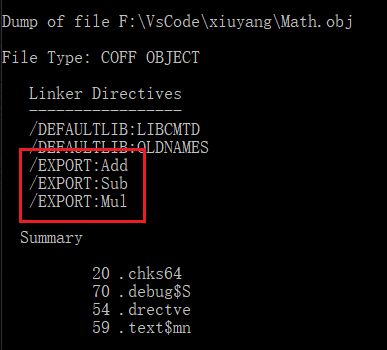
c. 怎么指定导出的符号
link Math.obj /DLL /EXPORT:Add(会生成三个文件)

9.2.2 EXP 文件产生的原因
链接器创建 DLL 时与静态链接一样采用两遍扫描过程:
第一遍:遍历所有目标文件并收集所有导出符号信息,创建 DLL 导出表。链接器把导出表放到创建 DLL 时产生的临时文件 EXP 中
- 第二遍:链接器把 EXP 和其他输入的目标文件链接在一起并输出 DLL
9.2.3 导入表
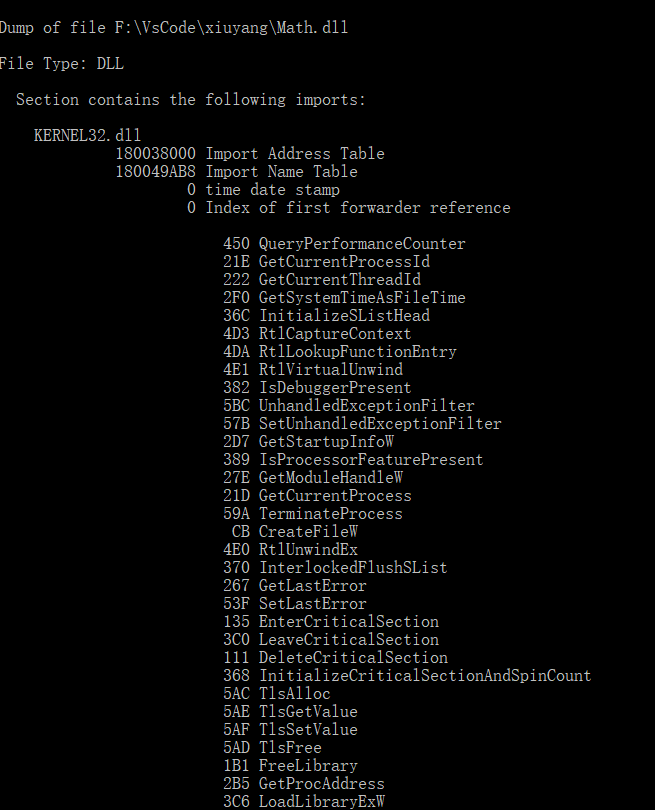
dumpbin /IMPORTS Math.dll查看导入了哪些函数
结构
FirstThunk 指向导入地址数组 IAT
1 | typedef struct _IMAGE_IMPORT_DESCRIPTOR { |
9.3 DLL 优化
- 重定及地址(Rebasing)
使用序号导入(只比函数名导入快一点点,另外,Windows API 的导入不能用序号,因为不同版本中函数名不变但序号是不断变化的)
DLL 绑定(导出函数地址保存到导入表)
9.4 C++ 与动态链接
使用 C++ 写动态链接库时,需要注意:

第四部分 库与运行库
第十章 内存
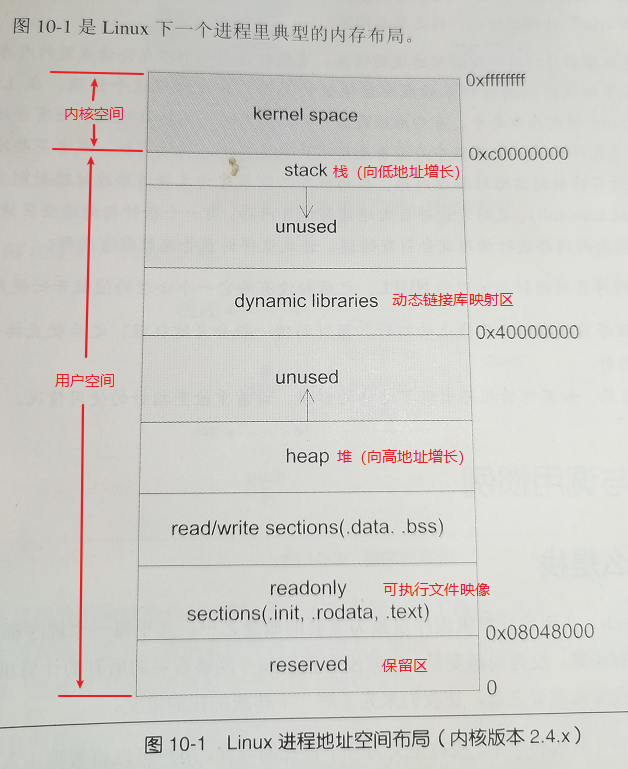
10.1 Linux 下进程地址空间布局
- 其中动态链接库映射区,用于映射装载的动态链接库。在 Linux 中,如果可执行文件依赖其他共享库,系统就会在 0x40000000 开始处分配相应的空间,将共享库载入该空间
Q&A
- Q: 程序出现“段错误(segment fault)”或者“非法操作,该内存地址不能 read/write”的原因
A: 这时典型的非法指针解引用造成的错误。最普遍的原因有两种
程序员将指针初始化为 NULL,之后没有给一个合理的值就开始使用
- 程序员没有初始化栈上的指针,指针的值一般会是随机数,之后就直接开始使用
- Q: 堆总是向上增长吗?
- A: 不是,Windows 里大部分堆使用 HeapCreate 产生,其不遵循向上增长这个规律。
10.2 栈与调用惯例
10.2.1 栈和堆栈帧
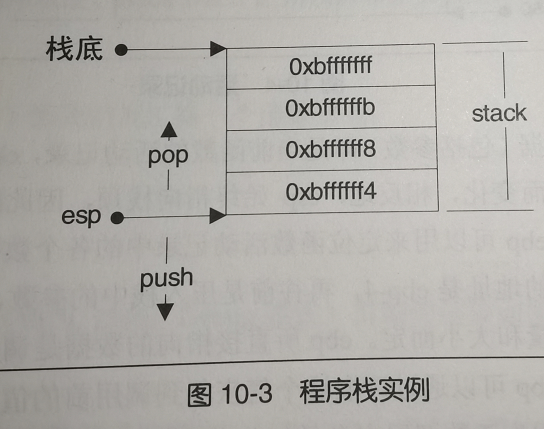
- 栈是向下(低地址)增长的,栈顶由 esp 寄存器进行定位。压栈使栈顶地址减小,弹出使栈顶地址增大。
- 栈保存了一个函数调用所需的维护信息:堆栈帧(或活动记录)
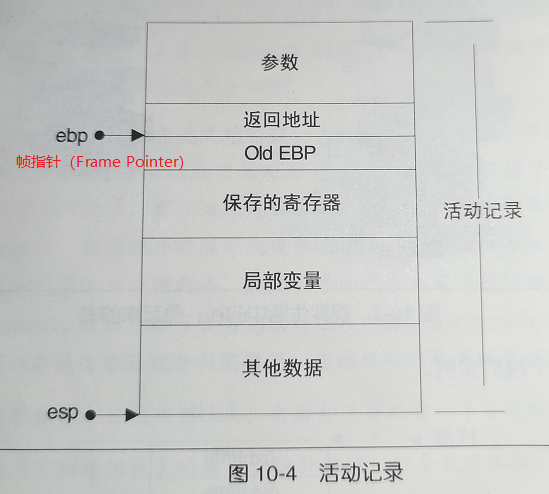
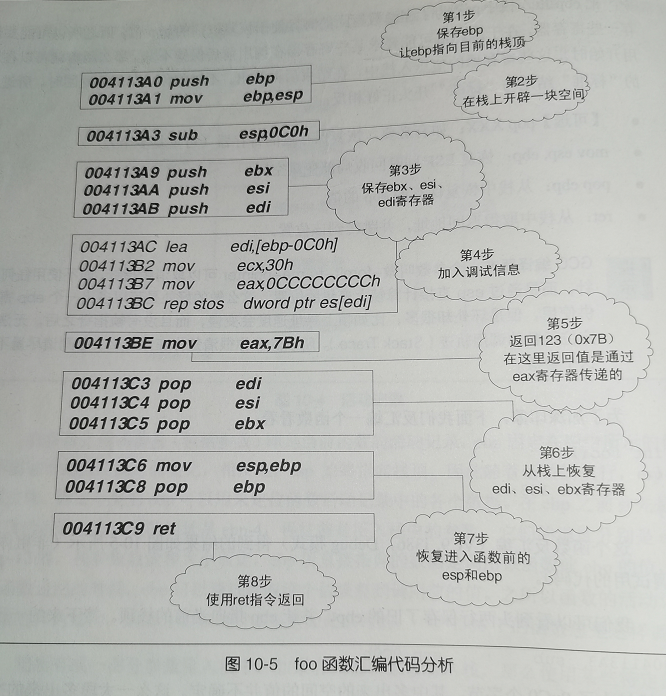
10.2.2 反汇编示例
- 示例代码
1 | int foo() |
10.2.3 烫烫烫烫..
Q:为什么常看到一些没有初始化的变量或内存区域的值是“烫”?
示例代码
1 | int main() |
加断点调试监视 p 的数据,会发现

- A:因为加入调试信息时,会将所有分配出来的栈空间的每个字节都初始化为 0xCC,两个连续排列的 0xCC 的汉字编码就是烫。
这仅作为变量是否已经初始化的参考,并不能以此为证据,有的编译器会使用 0xCDCDCDCDCD 作为未初始化标记,这时会看到汉字 屯屯
10.2.4 mov edi, edi
- 在 Windows 的函数里,有些函数尽管使用标准的进入指令序列,但在这些指令之前却插入了一些特殊内容:
1 | mov edi, edi |
这条指令暂时没有什么用处,在汇编之后会变成一个占用两个字节的机器码,纯粹为占位而存在。出于某些目的(如 Hook 技术),可以将占用两个字节的 mov edi, edi 指令替换成另一个 jmp 指令,原函数的调用就会被转换为新函数的调用。
10.2.5 调用惯例

10.3 堆
10.3.1 malloc 怎么实现的
程序向操作系统申请一块适当大小的堆空间,然后由程序自己管理这块空间,具体来讲,管理堆空间分配的往往是程序的运行库
- Q: malloc 申请的内存,进程结束后还会存在吗?
- A: 不会,进程结束后,会被操作系统关闭或回收。
Q: malloc 申请的空间是连续的吗?
A: 虚拟空间是连续的,物理空间不一定连续。
10.3.2 Linux 进程堆管理
Linux 下的进程管理稍微复杂些,它提供了两种堆空间分配方式,即两个系统调用:
brk()系统调用:设置进程数据段的结束地址mmap()的作用和 Windows 下的 VirtualAlloc 很相似:向系统申请一段虚拟地址空间
10.3.3 Windows 进程堆管理
VirtualAlloc()
首先通过 VirtualAlloc() 向系统一次性批发大量空间,然后根据需要分配给程序
分配算法位于 堆管理器(Heap manager),堆管理器提供了 API:
- HeapCreate
HeapAlloc
HeapFree
- HeapDestroy
10.3.4 堆分配算法
最基本的是空闲链表和位图
a. 空闲链表 (Free List)
- 概念:把堆中空闲块按链表的方式连接起来。用户请求一块空间时,遍历,找到合适大小的块并将它拆分;用户释放空间时把它合并到空闲链表中。
优点:实现简单
弊端:一旦链表被破坏,或者记录长度的四个字节被破坏,整个堆就无法工作。而这些数据恰巧很容易被越界读写接触到。
b. 位图 (Bitmap)
- 概念:把整个堆划分成大量的块(block),每个块大小相同。当用户请求内存时,总是分配整数个块给用户,第一个块作为已分配区域的头(Head),其余的作为主体(Body)。我们可以用一个整数数组记录块的使用情况,每个块只有 头、主体、空闲 三种状态,所以可以用两位表示状态,所以称为位图
优点:快、稳定、易于管理
弊端:
分配内存时容易产生碎片
- 堆很大或者块很小时,位图就会很大,可能失去 cache 命中率高的优势,而且会浪费一定的空间。(针对这种情况可以用多级位图)
c. 对象池
- 使用场景:被分配对象的大小是较为固定的几个值
- 概念:如果每次分配空间大小都一样,那就可以按这个大小作为单位,把整个堆空间划分成大量的小块,每次请求只要找一小块。